Classification Diffusion Models
Abstract
A prominent family of methods for learning data distributions relies on density ratio estimation (DRE), where a model is trained to classify between data samples and samples from some reference distribution. These techniques are successful in simple low-dimensional settings but fail to achieve good results on complex high-dimensional data, like images. A different family of methods for learning distributions is that of denoising diffusion models (DDMs), in which a model is trained to denoise data samples. These approaches achieve state-of-the-art results in image, video, and audio generation. In this work, we present Classification Diffusion Models (CDMs), a generative technique that adopts the denoising-based formalism of DDMs while making use of a classifier that predicts the amount of noise added to a clean signal, similarly to DRE methods. Our approach is based on the observation that an MSE-optimal denoiser for white Gaussian noise can be expressed in terms of the gradient of a cross-entropy-optimal classifier for predicting the noise level. As we illustrate, CDM achieves better denoising results compared to DDM, and leads to at least comparable FID in image generation. CDM is also capable of highly efficient one-step exact likelihood estimation, achieving state-of-the-art results among methods that use a single step.
Overview
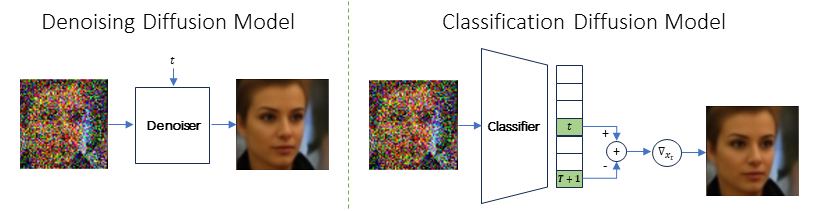
We introduce a diffusion based generative model that relies on a classifier for predicting the amount of white Gaussian noise added to clean samples. Our method relies on a theoretical relation between the optimal such classifier and the minimum-MSE denoiser for removing white Gaussian noise from samples. DDM functions as an MSE denoiser conditioned on the noise level, whereas CDM operates as a classifier. Given a noisy image, CDM outputs a probability vector predicting the noise level, such that the $t$-th element in this vector is the probability that the noise level of the image corresponds to timestep $t$ in the diffusion. To obtain the clean image with CDM, the MMSE denoiser is obtained as the gradient of the probability vector w.r.t the input image.

Numerical Evaluation
Negative Log Likelihood |
||
| Model | NLL ↓ | NFE |
|---|---|---|
| iResNet | 3.45 | 100 |
| FFJORD | 3.40 | ~3K |
| MintNet | 3.32 | 120 |
| FlowMatching | 2.99 | 142 |
| VDM | 2.65 | 10K |
| DDPM ($L$) | ≤3.70 | 1K |
| DDPM ($L_{simple}$) | ≤3.75 | 1K |
| DDPM (SDE) | 3.28 | ~200 |
| DDPM++ cont. | 2.99 | ~200 |
| RealNVP | 3.49 | 1 |
| Glow | 3.35 | 1 |
| Residual Flow | 3.28 | 1 |
| CDM | 3.38 | 1 |
| CDM(unif.) | 2.98 | 1 |
Fréchet Inception Distance |
||
| Sampling Method | Model | |
|---|---|---|
| CelebA $64\times64$ | ||
| DDM | CDM | |
| DDIM Sampler, 50 steps | 8.47 | 4.78 |
| DDPM Sampler, 1000 steps | 4.13 | 2.51 |
| 2nd order DPM Solver, 25 steps | 6.16 | 4.45 |
| Unconditional CIFAR-10 $32\times32$ | ||
| DDM | CDM | |
| DDIM Sampler, 50 steps | 7.19 | 7.56 |
| DDPM Sampler, 1000 steps | 4.77 | 4.74 |
| 2nd order DPM Solver, 25 steps | 6.91 | 7.29 |
| Conditional CIFAR-10 $32\times32$ | ||
| DDM | CDM | |
| DDIM Sampler, 50 steps | 5.92 | 5.08 |
| DDPM Sampler, 1000 steps | 4.70 | 3.66 |
| 2nd order DPM Solver, 25 steps | 5.87 | 4.87 |
Bibtex
Acknowledgements
This webpage was originally made by Matan Kleiner with the
help of Hila Manor
for SinDDM and can be used as a template.
It is inspired by the template that was originally made by Phillip Isola and
Richard Zhang for a colorful ECCV project;
the code for the original template can be found here.